NanoLLM - Optimized LLM Inference
NanoLLM
is a lightweight, high-performance library using optimized inferencing APIs for quantized LLM’s, multimodality, speech services, vector databases with RAG, and web frontends like
Agent Studio
.
It provides similar APIs to HuggingFace, backed by highly-optimized inference libraries and quantization tools:
from nano_llm import NanoLLM
model = NanoLLM.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct", # HuggingFace repo/model name, or path to HF model checkpoint
api='mlc', # supported APIs are: mlc, awq, hf
api_token='hf_abc123def', # HuggingFace API key for authenticated models ($HUGGINGFACE_TOKEN)
quantization='q4f16_ft' # q4f16_ft, q4f16_1, q8f16_0 for MLC, or path to AWQ weights
)
response = model.generate("Once upon a time,", max_new_tokens=128)
for token in response:
print(token, end='', flush=True)
Containers
To test a chat session with Llama from the command-line, install
jetson-containers
and run NanoLLM like this:
git clone https://github.com/dusty-nv/jetson-containers
bash jetson-containers/install.sh
jetson-containers run \
--env HUGGINGFACE_TOKEN=hf_abc123def \
$(autotag nano_llm) \
python3 -m nano_llm.chat --api mlc \
--model meta-llama/Meta-Llama-3-8B-Instruct \
--prompt "Can you tell me a joke about llamas?"
jetson-containers run \
--env HUGGINGFACE_TOKEN=hf_abc123def \
$(autotag nano_llm) \
python3 -m nano_llm.studio
If you haven't already, request access to the Llama models on HuggingFace and substitute your account's API token above.
Resources
Here's an index of the various tutorials & examples using NanoLLM on Jetson AI Lab:
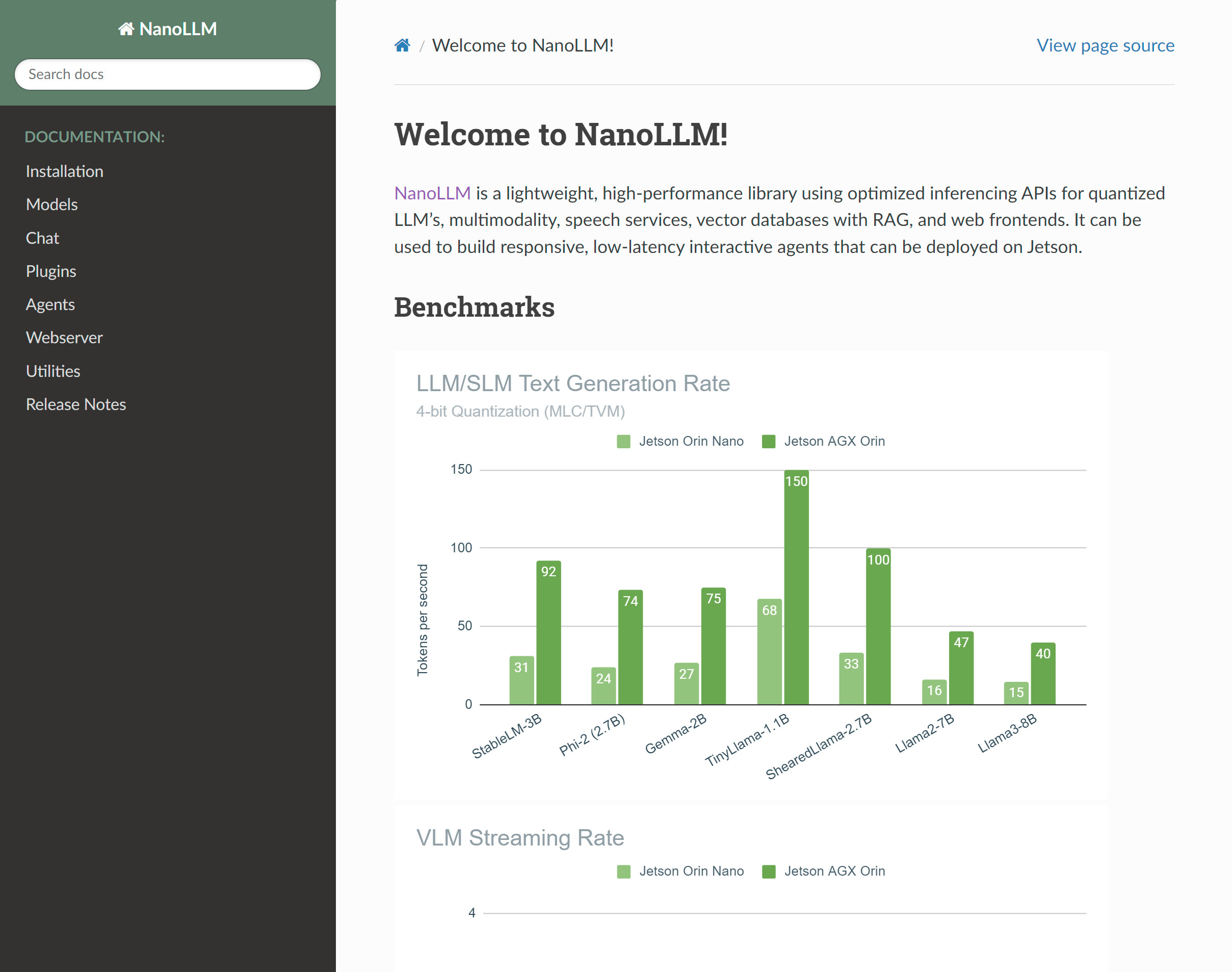
| Benchmarks | Benchmarking results for LLM, SLM, VLM using MLC/TVM backend. |
| API Examples | Python code examples for chat, completion, and multimodal. |
| Documentation | Reference documentation for the NanoLLM model and agent APIs. |
| Llamaspeak | Talk verbally with LLMs using low-latency ASR/TTS speech models. |
| Small LLM (SLM) | Focus on language models with reduced footprint (7B params and below) |
| Live LLaVA | Realtime live-streaming vision/language models on recurring prompts. |
| Nano VLM | Efficient multimodal pipeline with one-shot image tagging and RAG support. |
| Agent Studio | Rapidly design and experiment with creating your own automation agents. |
| OpenVLA | Robot learning with Vision/Language Action models and manipulation in simulator. |